연속 할당: 연속 할당은 값을 네트에 할당하는 데 사용됩니다. 연소 할당은 조합 논리 기능을 코딩하는 데 사용됩니다. 이러한 할당은 활성 이벤트 큐에서 업데이트되고 오른쪽 표현식 평가 시 업데이트됩니다. 연속 할당을 사용하는 동안 포트 또는 출력이 와이어로 선언됩니다.
assign y_out = sel_in ? a_in: b_in;
절차적 할당: 절차적 할당은 reg에 값을 할당하는 데 사용됩니다. 이들은 조합 논리와 순차 논리를 모두 코딩하는 데 사용됩니다. reg에 할당된 출력은 다음 할당이 실행될 때까지 유지됩니다. 이러한 할당은 절차 블록에서 always, initial 및 요구 사항에 따라 작업 및 기능 내에서 사용됩니다.
절차 블록에서 블로킹(=) 할당이 사용되면 활성 이벤트 큐에서 업데이트됩니다. 모든 논블로킹 할당(<=)은 활성 이벤트 큐에서 평가되지만 논블로킹 이벤트 큐에서 업데이트됩니다.
always@(posedge clk) // Sequential design description begin q_out<= data_in; end
always@ * // Combinational design description begin y_out = sel_in ? a_in : b_in; end
설계의 조합 루프
설계의 조합 루프는 위험하고 중대한 설계 오류 중 하나입니다. 동일한 신호가 여러 절차 블록에서 사용되거나 할당되는 경우 설계의 조합 루프가 발생합니다. 동일한 신호가 표현식의 오른쪽 또는 왼쪽에 있는 경우 설계에 조합 루프가 있는 것입니다.
조합 루프는 진동 동작을 나타내며 업데이트 단계에서 경쟁 조건을 가질 수 있습니다.
다음은 조합 루프의 예를 보여주고 있습니다.
always@(a) begin b=a; end
always@(b) begin a=b; end
위의 예에서 두 블록은 항상 동시에 실행되기 때문에 b를 업데이트하는 동안 b 값이 a에 할당됩니다. 이것은 디자인의 경쟁 조건입니다. 이 디자인은 이벤트로 인해 진동 동작을 생성합니다.
조합 루프는 합성할 수 없으며 합성 도구는 조합 루프에 대한 오류 또는 경고를 생성합니다. 조합 루프는 설계에 잠재적인 위험이 될 수 있으므로 피해야 합니다.
위의 예에서 볼 수 있듯이 always@(a) 블록은 이벤트 on에 감지되고 b 출력을 생성합니다. 결국 b 입력에 대한 변경 사항은 다른 always 블록 always@(b)를 트리거하고 출력을 생성하는 데 사용됩니다. 따라서 이것은 계속해서 진동 동작 또는 설계 조건 주변의 경쟁을 나타냅니다.
이 문제를 극복하기 위한 솔루션은 레지스터를 사용하여 다중 always 블록을 트리거하는 신호의 종속성을 피하는 것입니다. 레지스터를 조합 루프에 삽입하여 값을 업데이트할 수 있습니다.
always@(posedge clk) begin b<=a; end
always@(posedge clk) begin a<=b; end
조합 루핑을 방지하려면 논블로킹 할당을 사용하고 레지스터 논리를 사용하여 조합 루프를 끊습니다.
다음 예제는 두 always 블록은 클럭의 양의 에지에서 각각 a, b에 값을 할당합니다. 두 절차 블록이 동시에 실행되지만 논블로킹 할당은 NBA 큐에 대기되므로 다음 그림과 같은 구조가 생성됩니다.
설계상의 의도하지 않은 래치
래치는 활성 레벨 동안 명백하게 데이터를 출력으로 전송하므로 설계에 의도하지 않은 래치가 없어야 합니다. 의도하지 않은 래치는 설계 테스트 또는 DFT 중에 문제를 야기하므로 ASIC 설계에서 권장되지 않습니다.
STA 중에도 타이밍 알고리즘은 데이터를 클럭의 양의 에지에서 샘플링할지 아니면 음의 에지에서 데이터를 샘플링할지 이해할 수 없습니다.
다음 코드에서는 else 조건을 실행할 때 b_in에 대한 할당에 대한 정보가 제공되지 않으므로 래치를 유추하고 b_in의 이전 값을 유지합니다.
always@(c_in) begin if (c_in==1) begin a_in=1’b1; b_in=1’b1; end else begin a_in=1’b0; end end
다음 그림은 논리 표현을 보여주고 있습니다. if-else 구조는 멀티플렉서를 유추하고 b_in에 대한 할당이 else 내에서 누락되었으므로 활성화 입력 c_in에 의해 제어되는 양의 레벨 감지 래치를 유추합니다.
래치는 if-else 내의 불완전한 할당이나 케이스 구성을 사용하는 동안 다루어진 불완전한 조건으로 인해 추론됩니다. RTL을 코딩하는 동안 디자이너가 이것을 처리하는 것이 좋습니다.
다음 예제는 AND 게이트를 구현에 있어서 래치의 발생 예입니다.
else 조건이 누락되어 의도하지 않은 D 래치로 AND 게이트를 유추합니다. RTL 설계 엔지니어의 의도는 AND 게이트를 구현하는 것이지만 다른 것이 누락되어 래치 기반 설계를 유추합니다.
디자인 및 코딩 지침은 일반적으로 디자인 성능, 가독성 및 재사용성을 향상시키는 데 사용됩니다. 조합 설계는 설계가 최소 전파 지연과 최소 면적을 갖는 방식으로 코딩되어야 합니다.
Verilog를 사용하여 디자인을 설명하는 동안 항상 특정 코딩 지침을 따르는 것이 좋습니다.
Verilog 계층화된 이벤트 큐
Verilog는 절차 블록에서 두 종류의 할당을 지원합니다. 이러한 할당은 blocking(=) 및 non-blocking(<=) 할당으로 명명됩니다.
조합 논리 설계를 설명하는 동안 항상 blocking 할당을 사용하는 것이 좋습니다. 그 이유는 아주 간단하지만 그 이면의 근본을 이해하는 것이 중요합니다.
블로킹 할당을 이해하려면 계층화된 이벤트 큐의 개념을 이해해야 합니다. IEEE 1364-2005 Verilog 표준에 따르면 계층화된 이벤트 큐는 4가지 주요 영역으로 분류됩니다. 이러한 영역의 이름은 다음과 같습니다.
활성, 비활성, NBA 및 모니터.
Verilog 계층화된 이벤트 큐는 4개의 주요 영역을 가지며 아래에 설명되어 있습니다.
i. 활성 큐: 대부분의 Verilog 이벤트는 활성 이벤트 큐에서 예약됩니다. 이러한 이벤트는 임의의 순서로 예약하고 임의의 순서로 평가하거나 업데이트할 수 있습니다. 활성 큐는 블로킹 할당, 연속 할당, 논블로킹 할당의 RHS 평가(NBA의 LHS는 활성 큐에서 업데이트되지 않음), $display 명령을 업데이트하고 기본 요소를 업데이트하는 데 사용됩니다.
ii. 비활성 큐: #0지연 할당이 비활성 큐에서 업데이트됩니다.
Verilog에서 #0 지연을 사용하는 것은 좋은 습관이 아니며 이벤트 일정 및 순서를 불필요하게 복잡하게 만듭니다. 대부분의 경우 설계자는 #0 지연 할당을 사용하여 조건 주변의 경쟁을 피하기 위해 시뮬레이터를 속입니다.
iii. NBA 큐: 이 대기열에서 논블로킹 할당의 LHS가 업데이트됩니다.
iv. 모니터 큐: $monitor 및 $strobe 명령을 평가하고 업데이트하는 데 사용됩니다. 모든 변수의 업데이트는 현재 시뮬레이션 시간 동안입니다.
Verilog 블로킹 할당
블로킹 할당은 절차적 블록 내에서 순차적으로 실행됩니다. 할당 블로킹은 현재 할당을 실행하는 동안 절차 블록의 모든 후행 문을 차단합니다. 블로킹 할당의 실행은 항상 1단계 프로세스로 간주됩니다. 활성 이벤트 큐에서 차단 할당의 RHS가 평가되고 동일한 타임스탬프 동안 블로킹 할당의 LHS가 업데이트됩니다.
블로킹 할당에 대한 예제는 다음과 같습니다.
// Verilog RTL code using the blocking assignments reg a_reg, b_reg;
// Functionality of design always @ (a_reg or b_reg)
begin
a_reg=b_reg;
b_reg=a_reg; end
불완전한 감지신호목록
always 절차 블록을 사용하는 동안 감도 목록에 필요한 모든 신호 및 입력을 통합하는 것이 좋습니다.
다음은 2입력 NAND 로직의 기능을 설명하기 예제입니다.
합성 도구는 감지신호 목록을 무시하고 2개의 입력 NAND 게이트를 합성 가능한 출력으로 유추하지만 시뮬레이터는 입력 b_in의 변경을 무시하고 출력 파형을 생성합니다. 이는 시뮬레이션 및 합성 불일치로 이어집니다. 합성할 수 없는 구성을 사용하는 테스트벤치는 시뮬레이션 및 합성 불일치를 보고하도록 코딩됩니다.
// Verilog RTL code to understand the incomplete sensitivity list module logic_design( input a_in, input b_in,
output reg y_out) ;
// Functionality of design
always @ (a_in)
begin
if (a_in==1’b1 && b_in==1’b1) y_out = 1’b0;
else y_out =1’b1;
end
endmodule
//testbench to find the simulation and synthesis mismatch module test_logic; // Inputs reg a_in; reg b_in; // Outputs wire y_out;
// Instantiate the Unit Under Test (UUT) logic_design uut ( .a_in(a_in), .b_in(b_in), .y_out(y_out) );
always #25 a_in = ~a_in; always #40 b_in = ~b_in;
initial begin // Initialize Inputs a_in = 0; b_in = 0; // Wait 100 ns #100; end endmodule
감지신호 목록에서 b_in이 누락되어 있으므로 a_in = 1 및 b_in = 1일 때 y_out은 1입니다. 그러나 a_in = 1 및 b_in = 1일 때 NAND 게이트 출력은 0입니다. 따라서 시뮬레이션 및 합성 불일치가 발생합니다.
인코더의 기능은 디코더와 정확히 반대입니다. 인코더에는 n개의 입력 라인과 m개의 출력 라인이 있으며, 입력 라인과 출력 라인 사이의 관계는 n = 2m로 주어진다. 예를 들어 4:2 인코더를 고려해보자. 입력 라인의 수는 n = 4이고 출력 라인은 m = 2입니다. 4:2 인코더의 블록 다이어그램은 아래 그림과 같습니다.
우선 순위 인코더는 실제 응용 분야에서 사용되며 n개의 입력 라인과 m개의 출력 라인을 가지며 입력 라인과 출력 라인 간의 관계는 n = 2m로 주어집니다. 예를 들어 4:2 우선 순위 인코더를 고려해보면 입력 라인의 수는 n = 4이고 출력 라인은 m = 2입니다. 4:2 우선 순위 인코더의 블록 다이어그램은 다음 그림과 같습니다.
입력 In[3]이 가장 높은 우선 순위를 가지며 입력 in[0]이 가장 낮은 우선 순위를 갖습니다. 여기서 'X'는 상관 없음을 나타냅니다.
시스템 설계에서 대부분의 경우 디코더를 사용하여 메모리 또는 IO 장치 중 하나를 선택합니다.
디코더
디코더에는 n개의 선택 라인 또는 입력 라인과 m개의 출력 라인이 있으며 high 활성 또는 low 활성 출력을 생성하는 데 사용됩니다. 선택 라인과 출력 라인 사이의 관계는 m = 2n으로 주어진다. 한 번에 n개의 입력 라인의 논리 상태에 따라 출력 라인 중 하나가 하이 또는 로우가 됩니다.
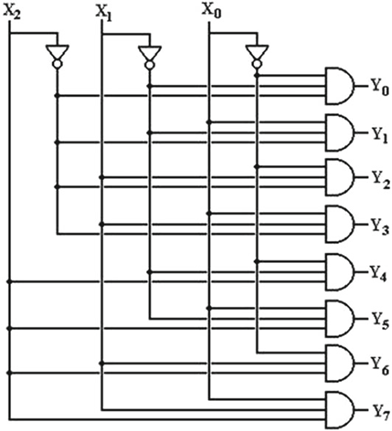
다음 그림은 3:8 디코더를 나타냅니다. 그림과 같이 X2, X1, X0은 선택 입력이고 Y0 ~ Y7은 하이 활성 출력 라인입니다.
다음 표는 디코더의 진리표입니다. 하이 활성 출력 디코더의 경우 한 번에 출력 라인 중 하나가 하이 활성됩니다.
X2
X1
X0
Y7
Y6
Y5
Y4
Y3
Y2
Y1
Y0
0
0
0
0
0
0
0
0
0
0
1
0
0
1
0
0
0
0
0
0
1
0
0
1
0
0
0
0
0
0
1
0
0
0
1
1
0
0
0
0
1
0
0
0
1
0
0
0
0
0
1
0
0
0
0
1
0
1
0
0
1
0
0
0
0
0
1
1
0
0
1
0
0
0
0
0
0
1
1
1
1
0
0
0
0
0
0
0
다음 그림은 하이 활성 인에이블 입력 en을 갖는 3:8 디코더의 상징적 표현입니다. 표시된 진리표는 활성 하이 활성화 en = 1을 갖는 디코더에 대해 양호합니다. en = 0일 때 디코더는 비활성화되고 출력 Y = 8'b0000_0000입니다.
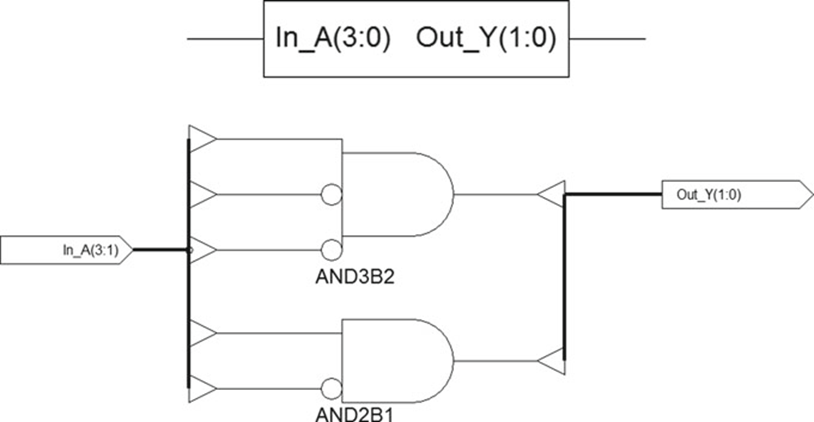
1 라인 대 2 또는 1:2 디코더에는 1개의 선택 입력 Sel, 인에이블 입력 En 및 2개의 출력 라인 Out_Y0 및 Out_Y1이 있습니다.
En
Sel
Out_Y1
Out_Y0
1
0
0
1
1
1
1
0
0
X
0
0
//Verilog RTL for 1 Line to 2 Line decoder with active high enable input module one_two_decoder_with_enable ( Sel, En, Out_Y1, Out_Y0); input Sel; input En; output Out_Y1; output Out_Y0; reg Out_Y1; reg Out_Y0;
always @ (Sel or En) begin if (En) case (Sel) 1'b0 : {Out_Y1, Out_Y0} = 2'b01; 1'b1 : {Out_Y1, Out_Y0} = 2'b10; endcase else {Out_Y1, Out_Y0} = 2'b00; end endmodule
2 Line to 4 Decoder with Enable 사용 사례
2 라인 대 4 또는 (2:4) 디코더에는 2개의 선택 입력 sel_in[1], sel_in[0], enable 입력 enable_in 및 4개의 출력 라인 y_out[3], y_out[2], y_out[1] 및 y_out이 있습니다.
2 라인 대 4 또는 (2:4) 디코더에는 2개의 선택 입력 Sel[1], Sel[0], 로우 활성화 입력 En_bar 및 4개의 활성 로우 출력 라인 Out_Y[3], Out_Y[2], Out_Y[1], Out_Y[0]이 있습니다.
En_bar
Sel[1]
Sel[0]
Out_Y[3]
Out_Y[2]
Out_Y[1]
Out_Y[0]
0
0
0
1
1
1
0
0
0
1
1
1
0
1
0
1
0
1
0
1
1
0
1
1
0
1
1
1
1
X
X
1
1
1
1
//Verilog RTL for 2 Line to 4 Line decoder with active low enable input and active low output lines module Two_to_Four_decoder(Sel,En_bar, Out_Y); input [1:0] Sel; input En_bar; output [3:0] Out_Y; reg [3:0] Out_Y;
always @ (Sel or En_bar) begin if (~En_bar) case (Sel) 2'b00 : Out_Y = 4'b1110; 2'b01 : Out_Y = 4'b1101; 2'b10 : Out_Y = 4'b1011; 2'b11 : Out_Y = 4'b0111; endcase else Out_Y = 4'b1111; end endmodule
//Verilog RTL for 2 Line to 4 Line decoder with active low enable input and for active low output lines module Two_to_Four_decoder(Sel,En_bar, Out_Y); input [1:0] Sel;
initial begin // Initialize Inputs sel_in = 0; enable_in = 0; // Wait 100 ns and then force enable_in =1 #100; enable_in =1 ;
// Wait 250 ns and then force enable_in =0 #250 enable_in =0;
end endmodule
2:4 디코더를 사용하여 4라인에서 16 디코더로
4 라인 대 16 또는 (4:16) 디코더에는 4개의 선택 입력 sel_in[3]: sel_in[0], 활성 로우 인에이블 입력 enable_in이 있으며 4개의 2:4 디코더를 사용하여 설계되었습니다. 각 2:4 디코더에는 4개의 활성 로우 출력 라인 y_out[3], y_out[2], y_out[1] 및 y-out[0]이 있습니다. 출력에 16개의 2:1 멀티플렉서가 있습니다.