4:1 MUX 사용 사례 구성
4:1 MUX는 case-endcase 구조를 사용하여 설명됩니다.
표시된 것처럼 case-endcase 구성은 병렬 논리를 추론하는 데 사용됩니다.
module mux_4to1 ( input [3:0] d_in, input [1:0] sel_in, output reg y_out);
always @*
begin
case ( sel_in )
2'b00 : y_out = d_in[0];
2'b01 : y_out = d_in[1];
2'b10 : y_out = d_in[2];
2'b11 : y_out = d_in[3];
endcase
end
endmodule

2:1 MUX를 사용하는 4:1 Mux
4:1 MUX는 2:1 MUX를 사용하여 구현할 수 있습니다.
4:1 MUX는 3개의 2:1 멀티플렉서를 사용하여 구현됩니다.

module mux_4to1 ( input [3:0] d_in, input [1:0] sel_in, output y_out );
reg tmp_1, tmp_2;
always @*
begin
case ( sel_in[0] )
1'b0 : begin
tmp_1 = d_in[0];
tmp_2 = d_in[2];
end
1'b1 : begin
tmp_1 = d_in[1];
tmp_2 = d_in[3];
end
endcase
end
assign y_out = (sel_in[1]) ? tmp_2 : tmp_1;
endmodule
멀티플렉서를 사용하여 조합 논리 설계
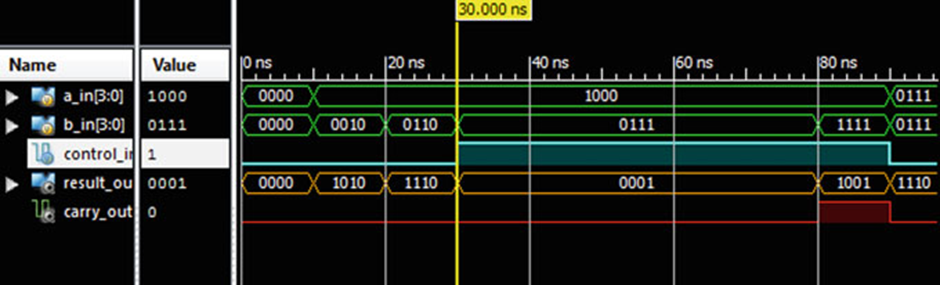
이제 합성 가능한 구조를 사용하여 다음 표에 표시된 단일 비트 가산기와 감산기를 구현해 보겠습니다.
if…else 구성의 사용으로 인해 추론된 논리는 출력에서 멀티플렉서 체인을 사용합니다.
| Control input | Operation | Description |
| 0 | a_in + b_in | Perform addition of (a_in, b_in) |
| 1 | a_in - b_in | Perform subtraction of (a_in, b_in) |
module add_sub ( input a_in, b_in, control_in, output reg result_out, carry_out );
always @ *
if (control_in)
{ carry_out, result_out } = a_in + b_in;
else
{ carry_out, result_out } = a_in + (~b_in) + 1;
endmodule
RTL 조정을 사용한 최적화 전략
위의 예제의 최적화 전략은 한 번에 하나의 연산만 수행하고 최소 리소스를 사용합니다.
module add_sub ( input a_in, b_in, control_in, output reg result_out, carry_out );
reg tmp_1;
always @*
{ carry_out, result_out } = a_in + tmp_1 + control_in ;
always @ *
if (control_in)
tmp_1 = ~b_in;
else
tmp_1 = b_in;
endmodule
'프로그래밍 언어 > Verilog' 카테고리의 다른 글
| [Verilog 학습] 인코더 (0) | 2022.04.14 |
|---|---|
| [Verilog 학습] 디코더 (0) | 2022.04.13 |
| [Verilog 학습] 멀티플렉서 (0) | 2022.04.11 |
| [Verilog 학습] Verilog 구성 및 조합 설계 2 (0) | 2022.04.10 |
| [Verilog 학습] 다중비트 가산기 및 감산기 (0) | 2022.04.09 |