반사 및 굴절의 기하학적 특성
그림자를 관찰하거나 레이저 포인터를 사용하여 가시광선이 어느 정도 직선으로 전파되는 것은 일상적인 현상입니다. 이 동작은 기하학적 광학의 관점에서 가장 쉽게 설명됩니다. 이 설명은 빛의 파장이 빛이 입사하는 물체/구조물의 크기보다 훨씬 작은 경우에 유효합니다. IR 방사선은 가시광선과 매우 유사한 특성을 보입니다. 따라서 기하학적 광학을 사용하여 종종 설명할 수도 있습니다.
∙ 균질한 재료에서 IR 복사는 직선으로 전파됩니다. 기하학적 법칙에 따라 전파되는 광선으로 설명할 수 있습니다. 일반적으로 광선은 화살표로 표시됩니다.
∙ 두 물질의 경계면에서 입사된 복사선의 일부는 반사되고 일부는 굴절된 IR 복사선으로 투과됩니다.
∙ 예를 들어 IR 카메라의 렌즈와 같은 균질한 재료의 광학 특성은 굴절률 n으로 설명됩니다. 이 지수 n은 비흡수성 물질의 경우 1보다 큰 실수이고, 흡수성 물질의 경우 복잡한 수학적 양입니다.
다음 그림은 기하학적 광학의 반사 및 굴절 법칙을 보여줍니다. 그림에 나와 있는 예는 공기에서 게르마늄 표면에 입사하는 IR 복사를 나타냅니다.

복사 측정 및 열 복사
IR 카메라를 사용한 실제 측정에서 물체는 카메라 방향으로 방사선을 방출합니다. 여기서 물체는 검출기에 초점을 맞추고 정량적으로 측정됩니다.
열화상 촬영은 대부분 IR 복사에 불투명한 고체 물체로 수행되기 때문에 방출은 물체의 표면만을 나타냅니다.
흑체 복사(Blackbody Radiation)
기본 물리학에 기초하여 0K 이상의 절대 온도에서 모든 물체는 방사선을 방출합니다. 어떤 물체가 방출할 수 있는 최대 복사 세기는 물체의 온도에만 의존합니다. 따라서 이 방출된 복사를 열 복사라고 합니다. 실제 물체의 경우 추가 재료 속성인 방사율이 작용합니다.
최대 복사 세기를 방출하는 방출기를 흑체라고 합니다. 흑체는 다음과 같은 특성을 갖는 이상적인 표면과 유사합니다.
1. 흑체는 파장과 방향에 관계없이 모든 입사 방사선을 흡수합니다.
2. 주어진 온도와 파장에서 흑체보다 더 많은 에너지를 방출하는 표면은 없습니다.
3. 흑체에서 방출되는 복사는 파장에 따라 다릅니다. 그러나 그 광도는 방향에 의존하지 않습니다. 완벽한 흡수체 및 방사체로서 흑체는 복사 측정의 표준 역할을 합니다.
흑체 복사에 대한 플랑크 분포 함수
흑체의 열복사에 대한 매우 정확한 스펙트럼 측정은 19세기 말까지 존재했습니다. 그러나 막스 플랑크가 그의 유명한 플랑크 상수 h 개념을 도입한 1900년 이전에는 측정된 스펙트럼을 만족스럽게 설명할 수 없었습니다. 플랑크의 이론은 열역학에 기반을 두었지만 복사의 방출과 흡수의 양자적 특성으로 인해 흑체 복사 이론 뿐만 아니라 물리학의 전 세계에 완전히 새로운 개념을 도입했습니다.
다음 그림은 –20 ~ 1000 °C 온도의 흑체 복사를 보여줍니다.
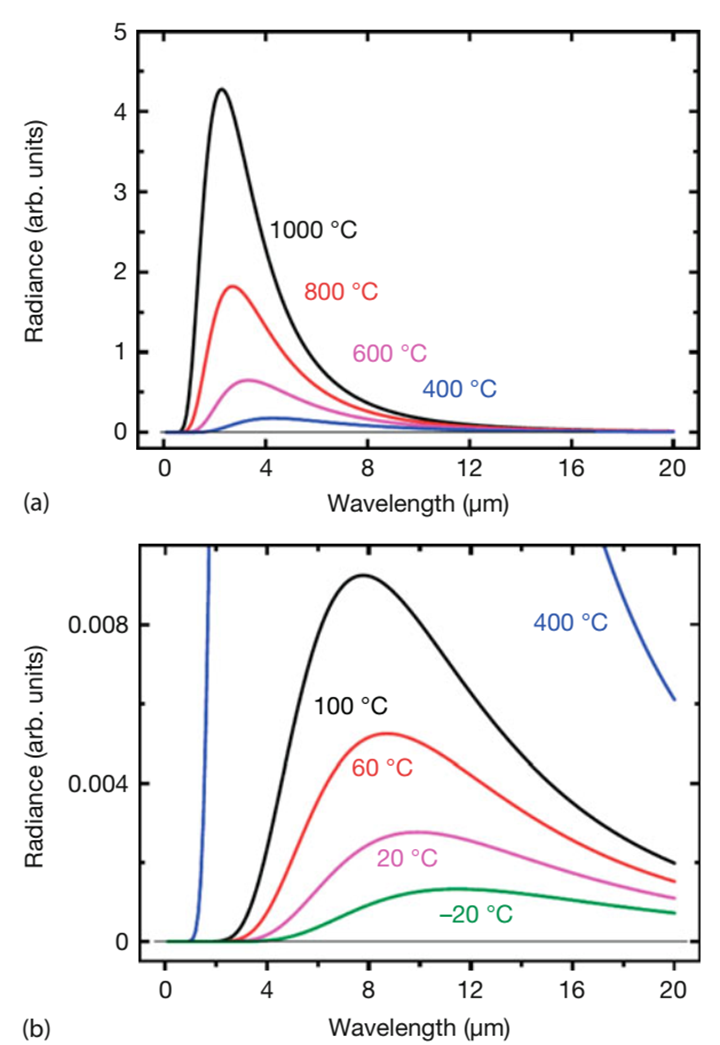
다음과 같은 몇 가지 특징이 있습니다.
1. 스펙트럼 램프의 방출과 달리 이러한 스펙트럼은 연속적입니다.
2. 고정된 파장에 대해 복사 휘도는 온도와 함께 증가합니다(즉, 다른 온도의 스펙트럼은 서로 교차하지 않음).
3. 방출 스펙트럼 영역은 온도에 따라 다릅니다. 낮은 온도는 더 긴 파장으로 이어지고, 높은 온도는 더 짧은 파장 방출로 이어집니다.
'열화상 카메라 (Infrared Thermal Camera)' 카테고리의 다른 글
| [열화상 카메라] 검출기 (0) | 2022.02.24 |
|---|---|
| [열화상 카메라] 방사율 계산방법 및 방사율 표 (2) | 2022.02.21 |
| [열화상 카메라] 방사율 개념 (0) | 2022.02.19 |
| [열화상 카메라] 방사율이란 (0) | 2022.02.18 |
| [열화상 카메라] 열화상 이미지 (0) | 2022.02.16 |

